
スクレイピングは自動でウェブページ上の必要な情報を抜き出せるので大変便利なのですが、いくつか気をつけることがあります。
そもそもクローリング、スクレイピングとは下記のような違いがあります。
- クローリング (crawling): ページからページに移動すること
- スクレイピング (scraping) : ページの情報を抜き出すこと
それでは、何を確認すべきか見ていきましょ。
結論
シンプルに結論を言うと、
- 私的利用で
- 情報解析が目的で
- robotx.txt の内容に従い
- ウェブサイトにログインなどせず
- 人間的なスピードで
- クローリング & スクレイピングする分にはなんら問題ない。
になります。
例えば、Google で特定のキーワードで検索し、結果のトップ 10 のサイトから、人間的スピードで H2 タグや URL を抜き取り、自分自身が情報解析することは問題ありません。そして、この動作を自動化しても問題ないです。
なんなら Googlebot はそうやってページをインデックスしているので、問題という方が問題です。。
ウェブ API の有無
まず、ウェブ API が提供されているか確認しましょ。
提供されていれば、スクレイピングする必要がなく JSON/XML などで簡単に欲しい情報が効率よく取得できます。
サイトのどこかに情報があるとは思いますが、「サービス名 API」で検索する方が早いと思います。
robots.txt の確認
複数ページをまたいでスクレイピングするときや、スクレイピングして良いサイトかを確認します。
一般的に、「ドメイン.com/robots.txt」にあり、クローラーに対し、どの URL にアクセスして良いか・ダメかが記述されています。
Google クローラー (Googlebot) もページをインデックスして良いかはこちらを確認していますね。
こちらが robots.txt のサンプルです。
User-agent: *
Crawl-delay: 6
Disallow: /wp-admin/
Disallow: /pdf/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://xxxxxx.com/oooo.xml- User-agent: 対象となるクローラーの種類 (「*」は、全てのクローラーを意味しています)
- Disallow: クロールを禁止するパス
- Allow: クロールを許可するパス
- Crawl-delay: クロールする間隔 ((秒)
- Sitemap: サイトマップの場所
より詳しい情報が知りたい方は、Google のドキュメント を参照ください。
Python 標準ライブラリの urllib.robotparser で robots.txt を解析することもできます。
こちらは 公式ページのサンプル になります。
クローラーはスクレイピングするためにあるので「Disallow: クロールを禁止するパス」はスクレイピング NG で、「Allow: クロールを許可するパス」は、利用規約に特別な記述がない限り、スクレイピング OK になります。
Amazon.co.jp の robot.txt を見てみる
実際に https://www.amazon.co.jp/robots.txt にアクセスすると下記のような情報が確認できます。
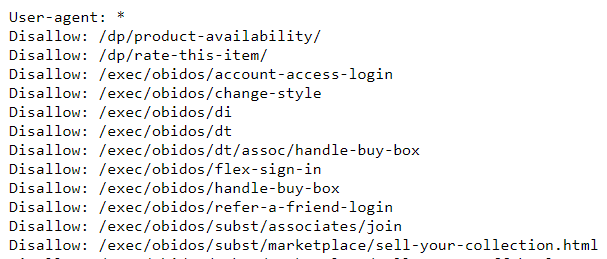
色々な「Allow: クロールを許可するパス」や「Disallow: クロールを禁止するパス」が確認できますね。
気になった方もいると思いますが、「利用規約に特別な記述がない限り」とは一体どういうことでしょうか?
実際に利用規約に何が書かれているのか見ていきましょ。
利用規約 (特に、著作権) の確認
先程に引き続き Amazon.co.jp の 利用規約 を見ながら、確認していきす。
著作権はどの範囲で、誰にあるのか?
こちらが Amazon.co.jp の著作権に関する利用規約です。

まとめると「Amazon.co.jp 内のすべてのコンテンツは著作権で保護されるので勝手に使わないでね❤」と書いています。
他にもページの下によくある「Copyright © 2017 〇〇〇 All Rights Reserved.」があれば、同様の意味になります。
ただ、よく勘違いしがちですが
「Copyright © 2017 〇〇〇 All Rights Reserved.」と書かれていなければ問題ない
は正しくありませんよ!
基本的に、自身で創作したコンテンツには (文章、デザイン、写真など)、自動的に著作権が発生 します。
なので、「Copyright © 2017 〇〇〇 All Rights Reserved.」と書いていなくてもそのサイトには著作権は存在しています。
侵害 (無断で自分のものかのように利用など) すれば訴えられますよ!
じゃー、何のための表記か?→ 単純に明示しているだけです。
ここで重要なのが「基本的に」とは言っているように、例外があります。
それは、私的使用のための複製 (著作権法第 30 条) で情報解析が目的 (著作権法 47 条の 7) など、著作権があるコンテンツでも法的に利用して良いということです。
サイトに著作権があり、情報解析目的で私的利用なら OK ということがわかりましたが、ではスクレイピングはして良いのでしょうか?
Amazon サイトってスクレイピング OK なの?
こちらが Amazon.co.jp のスクレイピングに関する利用規約です。

ちまたでは「Amazon サイトはスクレイピング NG」と一概にいっていますが、正しくありません。
この利用許可には、アマゾンサービスまたはそのコンテンツの転売および商業目的での利用、製品リスト、解説、価格などの収集と利用、アマゾンサービスまたはそのコンテンツの二次的利用、第三者のために行うアカウント情報のダウンロードとコピーやその他の利用、データマイニング、ロボットなどのデータ収集・抽出ツールの使用は、一切含まれません。
確かに、「ロボットなどのデータ収集」はダメと書かれていますが、利用規約の効力はユーザーが承諾して成り立ちます。
具体的には、Amazon アカウントを作成し、ログインしているときに効力が発生します。
実際にアカウント作成時に明確に記述されていますね。
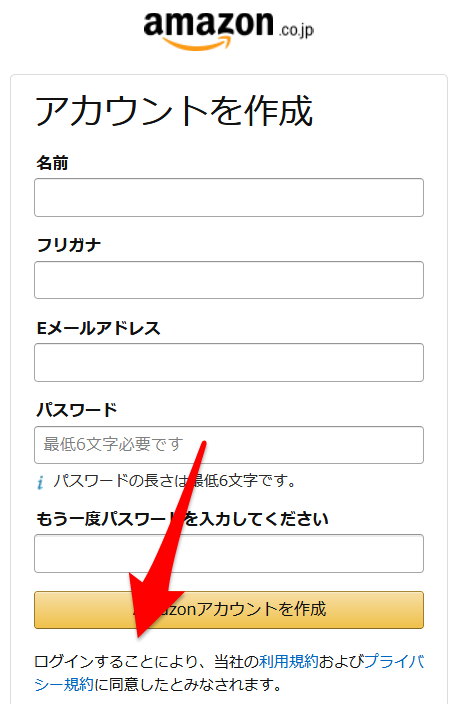
なので簡単にまとめると、ログイン (or 承諾) せずにスクレイピングしたサイト情報を、他人に提供したり販売はせずに、自分だけが利用する分には問題ないことになります。
サイトマップの確認
次にサイトマップを確認していきます。
こちらは、サイト内のページをクローリングする際に利用します。
ページ内のリンクを解析しながらページを辿るよりかは効率よくクローリングできますので、必要に応じて利用しましょ。
サイトマップの場所は、通常 robots.txt に記述されており、サイト運営者がクローラーに対してクロールして欲しい URL を明示しています。(一応「ドメイン.com/sitemap.xml」によく置かれています。)
サイトマップの仕様について こちら から確認できます。
ウェブサイトへのアクセス頻度
プログラム的に効率よく HTML から情報を抜き取るスクレイピングですが、通常の人間が行う操作より短時間でクローリングしながらページからデータを取得できてしまいます。
なので、かなりの高頻繁でウェブサーバーにアクセスしてしまい、他のユーザーの利用に影響がでる場合があります。
そのような迷惑をかけないためにも、間隔をあけてウェブサーバーにアクセスするようにしましょ。といった対応が必要となります。
つまり、人間がアクセスするスピードと同じスピードでクローリングした方が良い、になります。
一般的には、最低でも 1 秒以上の間隔はあけるべきとされています。
Python ライブラリ
どのサイトにアクセスして、スクレイピングをいつし、その情報をどう使えば良いかわかったところで、実際に Python でスクレイピングを行う際によく利用されるライブラリを見ていきましょ。
フレームワークとしてスクレイピングをサポートしているライブラリから、細かく動作をコーディングできるものまで幅広くありますので、スキルと利用用途に応じて自分に会ったものを選択しましょ。
Scrapy
Scarpy はクローリング & スクレイピング用のフレームワークです。
Twisted という非同期通信のフレームワークを利用しており、
- 効率がよい
- 非同期通信ができる
というメリットがあります。
Beautiful Soup
Beautiful Soup はスクレイピングに特化したライブラリで、「Python でウェブスクレイピング」といえば Beautiful Soup です。
オフィシャルページは、ドキュメントが充実しておりサンプルのたくさんあるので、初心者でもすぐに使えるライブラリです。
ただ、クローリングが必要な場合は、頑張ってコーディングするか scrapy を使うことになります。
urllib
https://docs.python.org/ja/3.7/library/urllib.html
urllib は Python の標準ライブラリなので、Python をインストールした時点ですぐに利用できます。
ウェブページにアクセスしたり、読み込んだりでき、スクレイピング用のライブラリです。
Requests
http://docs.python-requests.org/en/master/
Requests はサードパーティツールですが、オフィシャルドキュメントでも Requests のダウンロードを推奨しています。
pip install requestで可能なのであまり気にする必要は無いかもしれないですね。
urllib より直感的で使いやすいので、個人的にはすぐにインストールするモジュールの一つです。
ちゃちゃっと、RESTful API の情報を取得するのに向いています。
lxml
https://lxml.de/api/index.html
lxml は XML と HTML に何かしらの処理を行うのが得意なライブラリです。
また、処理も早くメモリの利用も効率的に行ってくれます。
なので、Scrapy や Beautiful Soup でも lxml 利用しています。
HTML や Python が使える人は、lxml & requests モジュールの組み合わせで自分好みの軽量なスクレイピングツールが作成できると思います。
残念なことに lxml のドキュメントは、初心者向けではないです。。。
Selenium
https://www.seleniumhq.org/docs/
Selenium は、ウェブアプリの自動テストツールです。
上記のライブラリは HTML レスポンスをそのまま扱うのに対し、Selenium はブラウザを立ち上げ、描画まで行います。
ブラウザで表示されている要素に対し処理が行えるため、 ゴリゴリに JavaScript で書かれたページを扱うのに向いています。
Selenium で JavaScript ゴリゴリなページを表示、Scrapy で HTML 要素を取得するなど、Scrapy と共に利用することもあります。
んで、どのライブラリ使えば良いの?
人それぞれ、好みや得意・不得意がありますが、個人的にはこのように使い分けています。
- ウェブ API とのやり取りは requests
- なんかわからんけど、とりあえずスクレイピングしたいなら Beautiful Soup
- クローリングが必要なら scrapy
- Javascript ゴリゴリページのスクレイピングなら Selenium
- HTML プロトコルを理解したいなら urllib & lxml
まとめ
自分をあるキーワードで Google 検索した際の順位や、複数のページにまたがった商品の価格を比較したり、ある一定の間隔で為替情報を取得したりとアイディア次第で利用用途は無限にあります。
サーバーに不可をかけないよう、ぜひお試しください!